






瑞士再保险:智能理赔文本清洗工具,解决重疾险理赔文本处理难题
自1994年国内第一张重疾险保单发售,中国重疾产品的发展已走过近30年。截至2018年底,行业重疾有效保单超过2亿件①,重疾相关理赔赔案约500万件②。
高层次的需求与挑战往往离不开底层数据的处理与应用。瑞再从重疾理赔信息入手,研发了基于人工智能的理赔文本自动化清洗工具,可快速清洗海量理赔文本,输出标准、统一的结构化理赔信息,延展应用于不同的重疾理赔数据集,从而提供更优质的理赔文本分析处理方案。
重疾理赔的关键信息往往以文本的方式记录在业务系统中,为了进一步分析重疾理赔经验,需要对重疾赔案进行加工处理。过去常见的做法是由理赔或者精算人员对赔案进行手工清洗。在样本量较小的情况下,这种方式具有快速、简单、易操作的特点,但随着理赔数据的快速不断积累,手工清洗的局限性越来越明显。

图1 手工清洗与自动化清洗的对照
受益于计算机技术的不断进步和发展,对于重疾理赔文本的清洗,瑞再提供了一系列持续优化的解决方案——基于人工智能的理赔文本自动化清洗工具。
入门
规则库
规则库以正则表达式为基础。正则表达式,又称规则表达式,是一个在传统计算机语言学领域当中广泛应用的算法。该方法旨在用特殊的字符规则描述、匹配给定文本当中需要匹配的字符串。
这种传统的、基于专业知识构建的规则库有着简便、快速、易调整的特点,对于短文本的清洗有着较高的有效性和准确率,同时,对于复杂的长文本清洗,基于规则库的方法也提供了一个初步但是快速有效的迭代起始点。
一个简单用于匹配甲状腺乳头状癌的
正则表达式示例
.*?((甲状腺).*(乳头状癌?)).*
进阶
统计模型
传统的机器学习文本挖掘算法,首先通过分词的方式,将一个文本变成一个由不同句子构成的句子集合,在这个基础上采用概率模型,如隐马尔可夫模型(HMM),将每一个句子变换成一个个的分词短语。通过这种处理,文本被细化为由各种关键短语所构成的短语集合,在该集合基础上,应用统计学的方式(比如单纯计数的Bag of Word的方式,或者强调了词语在文本和语料库重要度的TF-IDF 方法)将文本转换成计算机可以识别的向量表示,在此基础上适用于我们对应的业务场景。
这种描述文本的方法,优点在于快速、直接,即整个单词和文本由一种简单且直接的方式变换成数学表示,但存在一定的局限性。
1)在我们做文本向向量转换的时候,每一个分词短语转换成了一个向量表示,然而,这种方法并没有真正意义上捕捉到每一个分词短语的含义,每一个短语在文本当中周围单词的信息也没有在计数的方式中得到体现,更不要提及中文当中的同义词等对语义判断的影响。
2)在算法实施层面,用这种方式给出的文本表达是一个非常大的矩阵,而这个矩阵当中有非常多的数字零,因此计算效率不高。

图2 使用隐马尔可夫模型的示例。该马尔可夫模型由实际观测到的信息(图中的中文单词)和隐藏信息(英文字母)构成。隐变量当中,S代表单一字,B代表词组起始字,M作为词组中间字。隐马尔可夫就是使用概率论和动态规划的算法,通过可观测的中文,去判断正确的隐变量的组成方式,从而达成分词的目的。
高级
深度学习
深度学习引入了词嵌入、注意力机制等方法,很大程度上解决了单纯应用传统统计模型存在的问题。
词嵌入
我们可以通过word2vec的模型方案,建立起关键词和周围词的关系,相比于词袋模型,这样的词向量表示不再稀疏并带有一定的语义信息,这种表达方式被称为词嵌入(word embedding)③ 。
注意力机制
在模型训练时,另外一个重要的方法就是注意力机制。由于文本的序列化输入,传统的机器学习方法或者循环神经网络模型无法“记忆”历史信息。通过图3右可以清晰的看出注意力机制能够很好的考虑过往信息对当下信息的影响,从而有效的解决上述问题。

图3 经典的循环神经网络和注意力机制的神经网络对比④
近年来,随着在自然语言处理(NLP,Natural Language Processing)领域依靠词嵌入和注意力机制的预训练模型 + 模板学习的全新模型训练范式的兴起 ,我们可以直接使用已经被海量文本库训练好的大模型,从而极大了提高了模型效率。在此基础上,通过设计训练模板的方式 ,用少量但是经过专家标记过的数据,构建适用于目标文本的提示型模板,使得模型可以灵活的应用到下游任务。
瑞再研发的基于人工智能的理赔文本自动化清洗工具,创造性融合了上述规则库、现代自然语言处理方法以及深度学习模型。
在模型效率上,很大程度解决了在模型训练中对海量人工标签的依赖和专业人员的时间成本的问题;
在模型应用上,可以尽可能地适用于不同的理赔文本,输出标准化的理赔文本分类信息;
在模型输出上,融合的模型方案可以达到与专家清洗相一致的准确率。
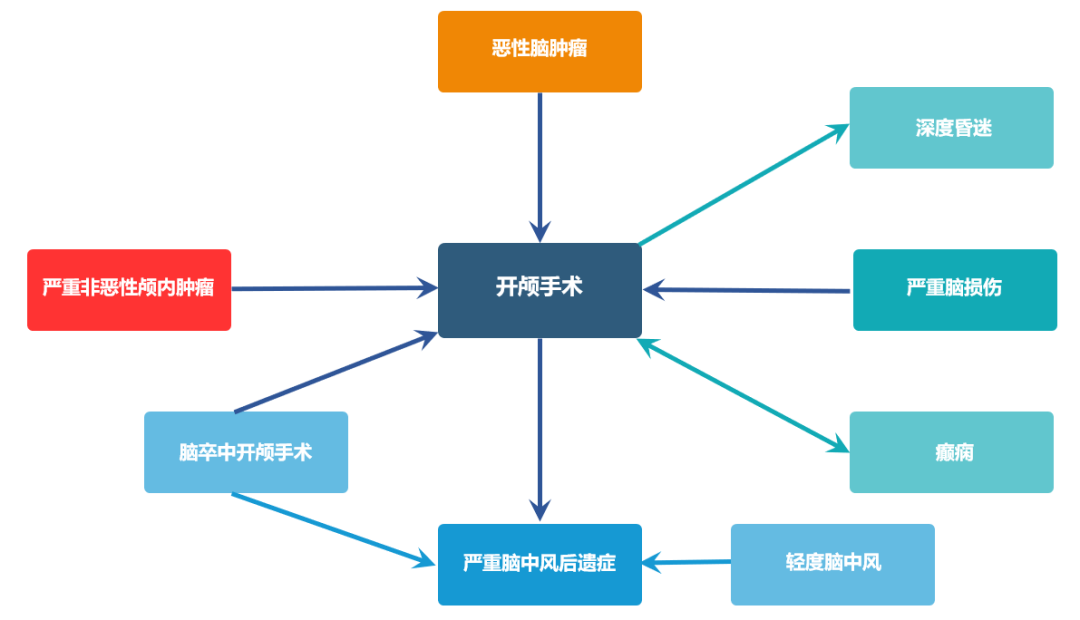
图4 疾病相关性图谱示例
通过瑞再智能理赔文本清洗工具搭建标准化、结构化的重疾理赔文本数据库,将极大程度拓展保险数据开发和应用的深度和广度。
传统经验分析的有效性和准确性得到进一步提升。如细化单病种经验,更加深入的剖析发生率变化的驱动因素,绘制疾病相关性图谱(图4)等。
有力地支持重疾产品的开发创新。如辅助开发心脑血管特定疾病产品、三高人群特定疾病产品、糖尿病人群特定疾病产品等,填补保障缺口,提升保险保障力度。
风险预警。通过后端经验追踪、分类数据监测更好地预测重疾病种发生率的未来趋势,助力重疾业务的可持续、健康发展。
▌本文作者
◆ 杨阳
瑞士再保险中国区寿险与健康险
高级定价创新精算师
◆ 党晓芊
瑞士再保险中国区高级数据科学家
◆ 宋晓莉
瑞士再保险中国区寿险与健康险
理赔专家
参考文献
① 中国精算师协会经验分析办公室. 中国人身保险业重大疾病经验发生率表(2020)编制报告.
② 中国精算师协会经验分析办公室. 中国人身保险业重大疾病经验发生率表(2020)编制报告.
③ Distributed Representations of Words and Phrases and their Compositionality,Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean. https://arxiv.org/abs/1310.4546
④ https://skymind.ai/wiki/attention-mechanism-memory-network



























































请先 登录后发表评论 ~