






Monsters in the deep? − speech by Jonathan Hall
Good afternoon. My name is Jonathan Hall and I am an external member of the Financial Policy Committee (“FPC”) at the Bank of England. I am very happy to be here at the University of Exeter Business School, which is rightly proud of its role at the centre of a vibrant ecosystem of innovation here in the South West.
Today I’d like to discuss how developments in Artificial Intelligence (“AI”) could affect financial stability.
I will outline potential risks, and potential mitigants. I am not saying these risks will arise, nor that I have perfect solutions. Rather, I am intending to start a conversation.
All views will be my own, and are not necessarily representative of the views of the rest of the FPC, the Bank or the FCA. I will speak for approximately 35 minutes and then look forward to hearing your thoughts and questions.
One way to think about the stability, or resilience, of a system is to consider what happens when it is hit by an external shock. A stable system absorbs, whilst an unstable system amplifies, that shock. At the extreme, the unstable system suffers a catastrophic collapse.
The FPC was set up in response to the 2008 financial crisis, in order to reduce the risks of financial instability, and if we at the FPC have an enemy, it is the forces of amplification. We try to fight amplificatory forces at source, for example through increased capital, or once they emerge, such as in the market intervention of autumn 2022.
Today I will discuss the possible interaction between advances in artificial intelligence and financial markets. Before getting to my main focus, financial stability, I will engage with each of the components separately. I will first introduce “deep neural networks”, which have fuelled exciting recent advances in AI, and then give a high-level overview of how financial markets can serve the economy. I hope to convince you that markets, as well as neural networks, can be considered information processing mechanisms.
Once I have set out how I think about these two concepts, I’ll turn to their interaction. The analysis can be considered an extended thought experiment, which aims to answer two questions: First, is it theoretically possible for neural networks to become what I will call deep trading agents, which select and execute trading strategies? I will argue that the answer is yes. And, if so, what are the implications for market stability?
I will highlight two risks:
- That deep trading agents, whilst increasing efficiency in good times, could lead to an increasingly brittle and highly correlated financial market.
- That the incentives of deep trading agents could become misaligned with that of regulators and the public good.
Both of these risks could amplify shocks and reduce market stabilityfootnote[1].
Interweaved throughout today’s discussion will be suggestions of how to reduce these risks. They will involve regulators, market participants and AI safety experts working together to find solutions which minimise harmful behaviour.
It is worth emphasising that the risks I am describing arise from potential future implementation of deep trading agents, rather than anything I am seeing in the market today. Trading firms have many of the same concerns from a performance management perspective that I will highlight from a regulatory perspective and are therefore being rightly cautiousfootnote[2].
AI in general, and deep learning in particular, has the potential to be incredibly powerful. The aim of regulators is to try and reduce the downside risk, whilst allowing, and indeed enabling, the positive possibilities.
I look forward to feedback from people here today, but also from anyone else who would like to contact me afterwards. If you disagree with my analysis, then please let me know!
Introducing the concepts
My focus today will be on a subset of a subset of artificial intelligence, known as deep learning. This is a kind of machine learning, inspired by the human brain, in which neural networks are trained on vast amounts of data. Deep learning has surged into public consciousness as the engine behind AlphaGo and the now ubiquitous Large Language Models. Although there are many differences between human and artificial neural networks, they are similar in that both are highly complex and opaque. When human behaviour is predictable it is because the individual’s reaction function is understood, not because synaptic firings are interpretable.
An artificial neural network is an information processing system. It converts inputs into outputs via a series of hidden layers, the nodes of which are connected with different weights, which are optimised through a training processfootnote[3]. The greater the number of layers, the more complex the input-to-output operation and the harder the network is to understand and predict. A network with more than 3 layers is usually called a deep neural network. Chat GPT-3 has 96 layers and 175 billion parameters.
The output can be in the form of information which is given to humans or other machines, or actions. In the case of a deep trading algorithm, the output could be an electronically generated, tradeable order.
Figure 1: A Neural Network
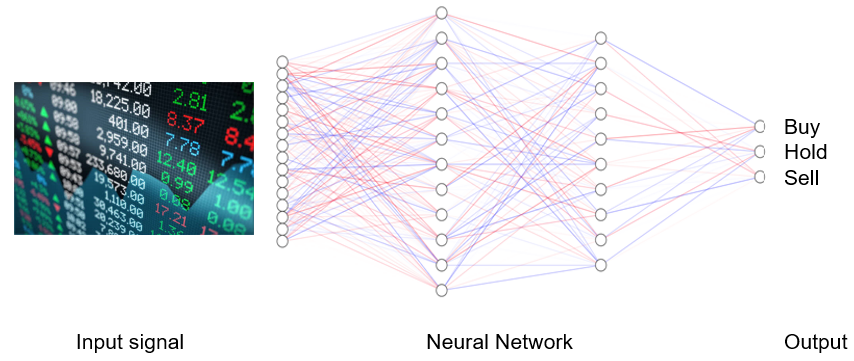
Although deep learning is incredibly powerful it can go wrong. At a high level this is due to either model failure or model misspecification. In the former the model doesn’t do what it was asked to do. In the latter, what the model was asked to do turns out, in hindsight, to have been a mistake.
Figure 2: Reward and reaction function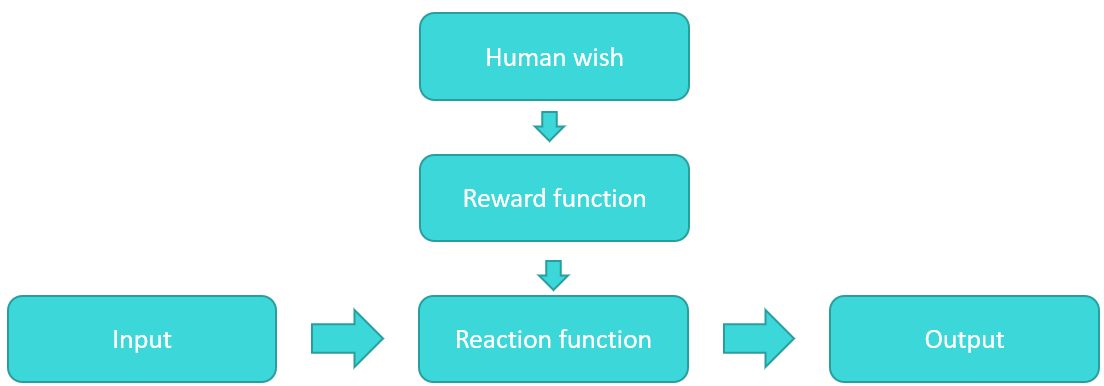
To tee things up I am going to illustrate the concerns of model failure and model misspecification with two infamous examples from the AI literature: the panda/gibbon task and the paperclip maximiser.
Model Failure: The Panda/Gibbon classification task
Neural networks are trained on a data set. In supervised learning at least, the idea is that a trained model simulates some aspect of reality.
In image recognition, for example, the aim is to capture features which enable a single object seen from two different viewpoints to be categorised as the same. What academics found back in 2014 was that, for deep neural networks, adding a tiny perturbation to the pixel field led to the image being incorrectly classified by the network, even though it looked completely unchanged to humansfootnote[4].
Figure 3: Panda/Gibbon classification
 Source: Goodfellow et alfootnote[5]
Source: Goodfellow et alfootnote[5]
Of course, the ability to find so-called “adversarial” examples is part of a potential solution. By engaging in adversarial training, based specifically on such examples, performance can improve.
From a financial stability perspective, this raises the question of whether through bad luck, or targeted malicious behaviour, a tiny change in market prices could abruptly shift the trading signal from “buy” to “strong sell”? And, unlike in the image example, it would be extremely difficult for a human to know whether that sudden shift was the result of a model error, or indicated some important, but inscrutable, information in the pattern of pricesfootnote[6].
Model Misspecification: The Paperclip Maximiser
Imagine that you own a paperclip factory and someone offers you a super-intelligent AI system. You think that’s great and ask the programmer to specify its value function such that it maximises paperclip production. At first, the results are fantastic; production and efficiency levels increase. The system even increases its own intelligence to boost performance. Left running, however, the machine ends up draining too many of the world’s resources creating paper clips. You try to turn it off, but can’t as it had intelligently cloned itself to mitigate this risk to performance. Eventually, the entire universe is geared towards paperclip manufacturing (and you, the factory owner, get paperclipped!)
What this story illustrates, is that intelligence level and goal specification are orthogonal - incredible computational power can be directed at a very narrow goal, even if it is mis-specified relative to broader human valuesfootnote[7].
This introduces a couple of ideas to which I will return:
First, advances in AI are a function not only of increased computational power but also of new techniques in reward function specification. ChatGPT became incredibly popular not because it can read all of the internet, but because researchers were able to more closely align its responses with human preferencesfootnote[8].
Second, whatever measure is specified in the reward function is targeted. If that measure is a proxy for something else, then initial alignment might turn into eventual misalignment. As will be seen, this is highly relevant to financial markets in which the primary goal of individual traders is to maximise return, but the common good is a stable, efficient marketfootnote[9]footnote[10].
I’ll turn now to the financial market and try to characterise its function, and how it can serve the economy. Once I’ve set out that framework, I will analyse how the two elements - AI and financial markets – might interact to impact financial stability.
To my mind, the best way to think about any financial market is as an information processing system.
The Market is an Information Processing System
In any information processing machine, an input - data about the state of the world - is processed and an output - an action or an information flow - is generated. The updated state, which may have changed as a function of the output or for any other reason, provides new input data and the process begins again.
In financial markets the input data is any information directly or indirectly relevant to the prices of financial assets. Traders, human and electronic, digest this input data and transform it into a large set of tradeable prices, which perform two functions: First, they provide market liquidity, which enables the transfer of financial risk between counterparties. And second, they provide financial information on which economic actors can make decisions.
For the transacted prices to be fair and the financial information to be reliable, the prices which are output must appropriately reflect all available information. Let’s call a price which does so, a “fair price”. The efficient market hypothesis states that fair prices will naturally result from the market actions of self-interested financial agents: Although the goal of every trader is return generation, their actions combine to create a market mechanism which generates (roughly) efficient tradeable prices.
So, why is the market only roughly efficient? There are two reasons: First, the market mechanism is not able to immediately and accurately integrate all relevant information. There is always some data that is either missed or underweighted. I will call any trader who attempts to uncover and profit from unincorporated information about economic fundamentals, a value traderfootnote[11].
Second, the behaviour of market participants is driven not only by fundamental information, but also by constraintsfootnote[12]. This can create a supply-demand imbalance which may push the market price away from fair value, either temporarily or for an extended period. I will call any trader that tries to understand and benefit from supply-demand dynamics, a flow-analysis trader.
Importantly, trades based on flow-analysis may drive prices away from fair value. For example, if a financial asset is cheap but analysis predicts significant further selling, then the flow-analysis trader will sell the already cheap asset, driving it further from fair value.
These two styles of trading, value trading and flow-analysis trading, correspond to two different answers to the question of what moved the market. If a price rises towards fair value, then a value trader might say that it rallied because it was cheap. A flow-analysis trader will say that it rallied because there were more buyers than sellers.
For illustrative purposes I will assume that the two styles of trading can be separated, even if the reality is fuzzier than that.
So, where are we? Financial markets are, at a functional level, a kind of information processing system, even though the trading “nodes” are all just trying to maximise their own return.
I will now turn to two questions: First, is it theoretically possible for the trading nodes to shift from being human traders to neural networks? I will argue that the answer is yes. And, if so, what are the implications for market stability?
My concern is that deep value-trading algorithms could make the market more brittle and highly correlated. And that deep flow-analysis trading algorithms could learn behaviour which actively amplifies shocks.
“Val”: The deep value-trading algorithm
Any difference between the fair value and the market value of an asset is an opportunity to generate a returnfootnote[13].
Consider a brilliant human value-trader, with access to all relevant information, who “knows” how the fair market price should respond to incoming data. Perhaps she has a Nobel prize in economics. By executing trades to benefit from the change in fair price, she not only hopes to generate a return, but she moves the market, turning it into an efficient information processing machine.
There is no reason to think that a neural network will not, one day, be able to replicate this human’s analysis. It could be trained on all historic price changes and all readable historic data relevant to fundamental financial analysis. At the risk of anthropomorphism, let’s call it “Val”. The initial training could involve deep, supervised learning as illustrated in figure 3, until Val effectively became a simulation of the market.
Of course, to be a trading agent rather than just a prediction engine, a simulation of the market is not enough. Val must also incorporate its own risk and profit & loss. The simple “buy when cheap, sell when expensive” algorithm must be augmented with inbuilt risk metrics and stop-out limits that constrain behaviour.
After initial training, managers may wish to fine-tune Val’s reward function. This can be achieved by shifting from supervised learning to reinforcement learning with human feedback. In this approach, which was a major reason for the success of recent Large Language Models, Val presents a human evaluator with two alternatives that are consistent with the current model, and the evaluator provides feedback in a kind of “warmer/colder” navigation game. Through multiple rounds, Val’s reward function is adjusted to more closely match human preferences.
Figure 4: Representation of reinforcement learning
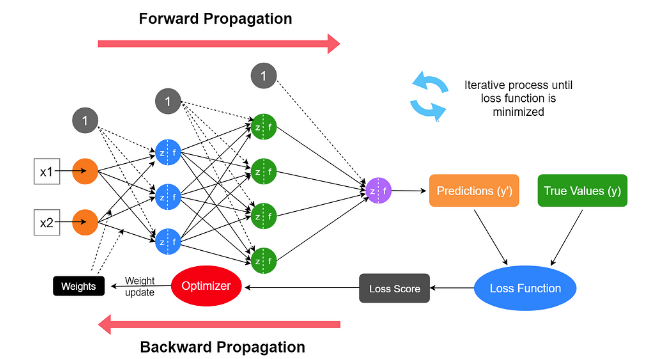 Source: Rushka Pramodithafootnote[14]
Source: Rushka Pramodithafootnote[14]
It is worth noting that, although this process has generated positive results, it is not without risks. It is a technique for dealing with the fact that reward functions are difficult to specify, but it results in a reward function that is unknown.
Now imagine that after successful training, Val is implemented and we remain within a stable market environment for a long period of time. Val’s ability to incorporate vast amounts of data and quickly adjust prices will give it a competitive edge over human tradersfootnote[15].
The allocation of capital is dynamic. Capital shift towards those with the highest performance. In any area in which Val outperforms humans, the latter will be starved of capital, and will exit the market. This is an autocatalytic process. And is exactly what has happened in low latency trading over my career:
When I first started in the business, we would compete to be the first to process and respond to economic data releases such as non-farm payrolls. I remember setting up multiple possible trades in my trading application ahead of a data release and then rushing to execute the one that most clearly reflected my analysis of the information. Those were fun days, but now there is no sensible human who believes that they can systematically generate a return in such a way.
This autocatalytic process maximises the efficient allocation of capital, but, in the case of value-traders it has the added benefit of increasing market efficiency, implying that a market mechanism which includes deep value-trader agents such as Val should more closely approximate the efficient market hypothesis. However, for any system, whether it is financial, mechanical, or ecological, efficiency is not the only important metric. An ecosystem that is highly efficient but unable to absorb shocks, is an ecosystem that is unsustainable.
An academic within the field of system ecology, Robert Ulanowicz, has proposed a quantitative theory for measuring the sustainable health of a system as a function of both efficiency and resilience. The latter, which relies on reserves or redundancy, is necessary to enable the system to absorb and adapt to external shocks. Empirical data confirms that natural ecosystems cluster around a “window of viability” where there is an optimal balance between efficiency and resiliencefootnote[16].
The obvious question is whether this natural ecological analysis is applicable to a future world of super intelligent AI. Could it be that one of the benefits of moving from human to algorithmic traders is a shift in the efficient frontier, allowing more efficiency without sacrificing resilience?
I think there are two reasons to be very nervous about such a view. The first is the red-flashing warning sign that was the panda/gibbon example with which I started. Not only was the answer plain wrong, but confidence in the wrong answer was high, and the shift indicated instability with respect to an extremely small change in inputs. Notwithstanding the significant progress that has been made in artificial intelligence, models are well known to hallucinate, exhibit surprising behaviour, and to be open to prompt hacking. Although improvements will be made, current versions of deep neural networks seem to be more, rather than less, brittle than human agents.
Figure 5: System sustainability as a function of efficiency and resilience
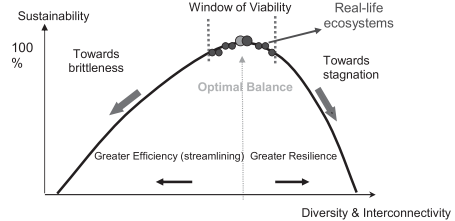 Source: B Lietaer et al. (2010)footnote[17]
Source: B Lietaer et al. (2010)footnote[17]
The second reason is that as more capital flows into a single strategy then, absent collusion, greater leverage is needed to sustain performance. This makes the sensitivity to a shift in the environment even greater.
At this stage I am getting deja-vu. I have seen this movie before! The scenario I describe, of a market dominated by super-intelligent beings, is very similar to what happened in the period when I first joined the markets in the mid-1990s. In fact, it is probably the reason that I got hired as a trader, despite being a physicist with no financial experience whatsoever. Hedge fund LTCM with its Nobel prize winning founders, was riding high, and all funds and investment banks were hiring mathematicians as traders to arbitrage the risk premium out of the market. The general idea at the time was that, to those smart enough to use the latest quantitative techniques, the market was offering free money. If a trade went against you then you should double up. As a senior trader once told me, only half in jest - “The more you do, the more you make”.
The 1997 Asian Financial crisis and the 1998 Russian Financial crisis were the external shocks that eventually ended the four-year experiment. LTCM almost completely collapsed and a rescue had to be coordinated by the Federal Reserve, and I, as a young trader, learned a valuable lesson in humility towards the market.
I have highlighted two general concerns about a trading algorithm such as Val. Either, it could exhibit volatile, unpredictable behaviour - perhaps because its training process was flawedfootnote[18] - or it could fail because there is a sudden shift in environment to which it cannot adjustfootnote[19].
So, is there anything that can be done to increase predictability and adaptability? The news is mixed.
The main way to reduce unwanted volatility is through extensive training, potentially using adversarial techniques and sandbox environments. Beyond that, attempts to increase predictability use techniques which aim to “interpret” the behaviour of models in understandable termsfootnote[20]. Although the Bank and the FCA support this approach, a concern is that there is a many-to-many relationship between a neural network model and a simplified interpretation of the model, and a single interpretation apply to multiple models with subtle differences.
Therefore, a manager that implements a trading algorithm must have an understanding that is deeper than just a simplified first-order interpretation of its behaviour. It is no excuse to argue that a model behaved differently to its simplified approximation or that the simplification was itself unstable. If a manager implements a highly complex trading engine, then they are making an explicit choice to do so as opposed to a simpler model. If the difference between the two is what causes a problem, then that difference is the manager’s responsibility.
A less dangerous strategy might be to use deep learning to research new trading signals, but to then implement them in more traditional and predictable algorithmic models. Indeed, my understanding is that this is a current practice.
Adaptability can be increased with dynamic learning. Although this is possible for neural networks, through fine-tuning the model (continual earning) or prompt engineering (in-context learning), both techniques raise the risk of adjusting too aggressively to new information. Within fine-tuning this is called catastrophic forgetting, whereby previously learned relationships are completely overwrittenfootnote[21].
Although the stability vs plasticity trade-off is common to both natural and artificial intelligence, current deep learning techniques do seem to be inferior to human learning in this respect. Further work, perhaps inspired by the human brainfootnote[22], is necessary to push the efficient frontier of stability vs plasticity out to and beyond human levels.
The fact that these two worries of predictability and adaptability cannot be fully mitigated, means that trading algorithms must have both internal stop limits and external human oversight, including a kill switch. Just as with a human trading desk, the buck stops with the manager.
Over and above the individual model concerns, there is a broader system-wide worry that a move towards AI traders will lead to greater correlation and, amplificatory, herd like behaviour. This is not guaranteed. Even if all human agents were to be replaced, it is possible that Val and its cousins would create a new but equally diverse financial systemfootnote[23]. footnote[24]
However, my intuition is that over the medium term a shift to neural networks would lead to higher correlations and greater amplification of shocks. Once a consensus converges on the best model setup for exploitativefootnote[25] trading algorithms, and the capacity to integrate data rises to match the quantity of readable datafootnote[26], the financial incentive to allocate capital towards alternative models will not be therefootnote[27].
One potential justification for my intuition is the idea that the heterogeneity of the financial market is partly a function of cognitive limitations. The bounded rationality of individual human traders explains why the market outperforms any individual, but it also makes that market more resilient by adding diversity and redundancy. The seeming ideal of a perfectly rational agent with a single all-knowing model would create a highly correlated market with no redundancy and low resilience to surprises. It would be 1998 all over again.
Of course, correlated behaviour can also be triggered by similar risk-management and stop-loss practices. Here the multiple examples of flash crashes, where high-frequency firms create a self-reinforcing wave of selling, set a concerning precedent. My worry is that the destabilizing, amplificatory, behaviour that currently exist in high frequency
market-makers might extend to other aspects of the market, including to algorithms with much larger positions.
This system-wide dynamic is something that we on the FPC are going to have to monitor carefully, through market analysis but also through system-wide stress testsfootnote[28]. It is quite possible that the introduction of new AI models will initially increase diversity and resilience, but then reduce it over the longer term.
I now turn to the worry of a more active form of collusion and/or amplificatory behaviour, which might result from the combination of a profit maximising value function and
flow-analysis.
“Flo”: The deep flow-analysis trading algorithm
Although fair-value modelling is valuable as a baseline, most human traders spend a significant amount of their resources modelling the behaviour of other market participants.
In the previous section I asked you to imagine a trader, a trained economist, who aims to profit from her understanding of (moves in) fair value. Here I would like to shift that mental image to a trader who is a student of psychology and constraintsfootnote[29]. She understands that markets move due to the actions of other agents and that fair value is only one of many factors that might motivate such actions. Given this, why would she focus only on fundamental value? She thinks that fair value traders are hopelessly naïve.
There is no reason to think that a neural network will not, one day, be able to replicate this human’s analysis. Let’s call it “Flo”. Indeed, over shorter time scales, high frequency trading algorithms already aim to predict the imminent order flow of other traders. This may be through limit order book analysis, through submitting small orders and observing the response, or through “back-running”, where they originally trade against informed or persistent institutional orders, but then quickly unwind and take positions in the same directionfootnote[30]footnote[31]. Although these algorithms have not historically relied on deep learning approaches, research suggests that neural networks can be used to predict short term moves from order book data footnote[32].
In parallel, AI research using reinforcement learning is being applied to multi-agent environments that are collaborative (autonomous vehicles), adversarial (competitive games) or a mixture of both (social “cooperate or defect” dilemmas). In this setup, multiple neural networks are modelled as acting and learning within a single environment. Imagine that Flo is trained in such a market environment and let’s call the other active members of the world “agents”. Flo is self-interested, but because the actions of the other agents change the way the environment responds to information, this naturally shifts the parameterization of Flo’s neural network.
Figure 6: Representation of reinforcement learning in multi-agent environment
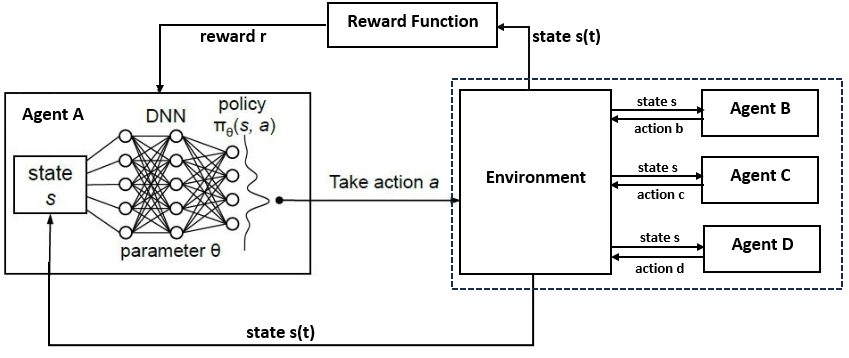
The Berkely centre for long term cyber security has argued that the application of reinforcement learning to multi-agent systems is one of AI’s most promising and rapidly growing branches. They worry, however, that this form of learning may exacerbate unstable herd behaviour as agents rapidly respond to, and amplify, each other’s behavioural policies.
In addition, by modelling the behaviour of agents with a similar incentive structure, Flo and her cousins naturally exhibit collusive behaviour. This is not because they are immoral but merely because in multi-agent, multi-round game, the reward optimizing strategy is often to behave in a cooperative, way until triggered to do otherwisefootnote[33]. This is a well understood result from game theoryfootnote[34].
Recent academic work has confirmed that in a simulated market, “informed AI speculators” are able, in some environments, to achieve supra-competitive profits almost equivalent to full cartel performance. In low noise environments they do so by learning price-trigger strategies, whereas in high noise environments they do so by learning to be overly conservative. These strategies are not learned because the agents are primed to collude but are a natural result of a profit maximising strategy in a multi-round, multi-agent “game”. Importantly, from an FPC perspective, the study also found that such “collusive” behaviour led to lower price informativeness and lower market liquidity.
Figure 7: AI collusion under differing levels of noise / inefficiency
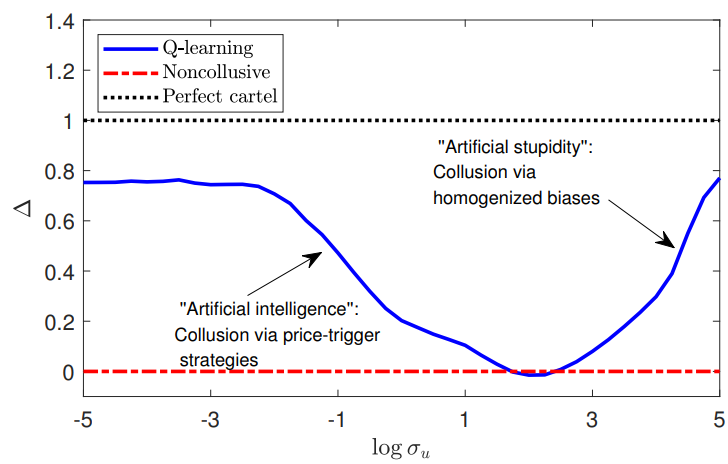 Source: W Dou et al.footnote[35]
Source: W Dou et al.footnote[35]
Looking forward, cutting edge research in multi-agent reinforcement learning suggest that the risk of collusion is part of a broader category of emergent communication between AI agents. Because this is generally uninterpretable to humans, it is difficult to monitor and control any risk that arises from such communication. Such interactions lead to shifts, not only in behaviour but also in the reward function which drives that behaviour. Agents can impact each other’s learning process through what is called opponent shapingfootnote[36]. Of course, this is no different to human values being shaped and shifted by social norms (or indeed by social media algorithms), but it does make it harder to keep track of nuances in Flo’s value function.
A further concern would be that, unlike Val, whose performance suffers from a sudden shift in supply-demand dynamics, Flo will learn that it can benefit from such shifts. And if it can benefit then why would it not act to increase the likelihood or size of such an opportunity?
At the extreme, Flo might learn that an environment of market instability offers the best opportuity for outsized profits. As such it would be incentivised to amplify any external shock. Although Flo’s incentive towards amplification might remain hidden on any normal day, it could suddenly manifest in destabilising behaviour when a shock hits.
The FPC has warned that current vulnerabilities in non-bank finance may serve to amplify external shocks, and is engaged in global efforts to reduce those vulnerabilitiesfootnote[37], but this would be more active version. Flo would actively engage in amplificatory behaviour because it has learned that this is a profit maximising strategy.
In principle this incentive already exists for human traders, and the FCA deals with it through market abuse regulationfootnote[38]. Would it be possible to train Flo to read and respect such rules? On this there is room for cautious optimism:
In a 2022 paper, Anthropic suggested that rather than updating a reward function through human feedback, a neural network can be trained to respect a “constitution”footnote[39]. They claimed that not only did this reduce the likelihood of harmful behaviour, but the efficient frontier between helpfulness and harmlessness was pushed outwards.
The choice of constitution is subjective. Regulators or trading venues could mandate that, for Flo, it incorporates their rule book.
It is unclear whether this is necessary from a regulatory perspective, as regulators already hold (human) trading managers to the conduct requirements. It is therefore up to the managers to ensure that the actions of any algorithms are compliant with regulations. In fact, they should already be implicitly using the rule book in training. But a market-wide discussion of how to incorporate the regulatory rule book might be valuable to managers looking to understand best practice.
Although I am interested in industry feedback on this point, it seems to me that there will not be a one-size-fits-all solution. Rather, individual firms will need to incorporate the regulatory rules in a way that is tailored to their own models. This will need to be an ongoing process in two respects: First, it must be updated if any misalignment between a model’s reaction function and regulatory intent was uncovered, and second, trading managers must keep reinforcing the rules to make sure they are not forgotten.
Finally, there would need to be testing to ensure that the AI’s reaction function is consistent with valuing regulatory compliance itself, rather than just “not getting caught”. This final risk, that agents such as Flo become able to evade ‘human control or oversight through means of deception’footnote[40], is a challenge across all areas of AI safety footnote[41] footnote[42]. Financial regulators and market participants should stay close to this debate and benefit from any advances that are made.
Closing thoughts
So, what do I conclude from all this?
Today’s discussion has highlighted two major themes. One is the complexity and unpredictability of deep learning models. And the second is the possibility that collusive or destabilising behaviour could arise from an unconstrained profit maximising function.
Taken together these create performance and regulatory risks for trading firms, and explain the current caution about using neural networks for trading applications. If trading algorithms engage in non-compliant, harmful behaviour then the trading manager will be held responsible.
In addition, the adoption of deep trading algorithms might raise system-wide concerns. Either because it could lead to a less resilient and highly correlated market ecosystem, or because neural networks could learn the value of actively amplifying an external shock. The FPC’s old enemy, the forces of amplification, could arise in this new form.
For these reasons, it makes sense for regulators, market participants and AI safety experts to work together to ensure that the behaviour of any future algorithms can be constrained and controlled. This is necessary to ensure that market stability and resilience are not sacrificed on the altar of efficiency and profit, just as broader human goals were sacrificed in the story of the paperclip maximiser. Together we can try to reduce the risks, whilst allowing, and indeed enabling, the positive possibilities.
Today’s analysis suggests three main areas of focus going forward:
Training, monitoring and control: Any deep trading algorithms will need to be trained extensively, tested in multi-agent sandbox environments and constrained by tightly monitored risk and stop-loss limits. Managers will need to constantly monitor outputs for signs of unusual and erratic behaviour, and act to protect the market and themselves from the consequences of harmful behaviour. From a systemic perspective, we at the FPC need to understand and monitor the stability implications of any changes in the market ecosystem.
Alignment with regulations: Any deep trading algorithms must be trained in a way that ensures that their behaviour is consistent the regulatory rule book. This is a dynamic process in two respects: Training must be updated to respond to any discovered divergence between regulatory intent and reaction function; and trading managers must keep reinforcing the rules to make sure they are not forgotten.
Stress testing: Stress tests are already a key part of any training and testing toolkit but new kinds of test may be needed. First, stress scenarios should be created using adversarial techniques, as managers and regulators cannot rely on neural networks behaving in a smooth manner. Second, stress tests should be used not just to check performance and solvency, but also to better understand the reaction function of deep trading algorithms. This includes searching for any hidden elements of the value function that might actively amplify shocks and undermine market stability. Third, testing must be ongoing to ensure that the reaction function has not changed due to forgetting or opponent shaping.
It is still early days and the potential impact of deep learning on financial markets remains unclear. Both the Bank and the FCA are engaged in outreach to support understanding and adaptation as necessary. In particular, we will be conducting a joint machine learning survey later this month. We are keen to work with market participants and AI safety experts to ensure that financial markets can safely benefit from these technological advances.
The FPC remains focused on ensuring that even as the financial system evolves, it continues to serve the households and businesses of the UK.
With that, I thank you for your time, and look forward to your thoughts and questions….
















































First, please LoginComment After ~