






瑞士再保險:智能理賠文本清洗工具,解決重疾險理賠文本處理難題
自1994年國內第一張重疾險保單發售,中國重疾產品的發展已走過近30年。截至2018年底,行業重疾有效保單超過2億件①,重疾相關理賠賠案約500萬件②。
高層次的需求與挑戰往往離不開底層數據的處理與應用。瑞再從重疾理賠信息入手,研發了基於人工智能的理賠文本自動化清洗工具,可快速清洗海量理賠文本,輸出標准、統一的結構化理賠信息,延展應用於不同的重疾理賠數據集,從而提供更優質的理賠文本分析處理方案。
重疾理賠的關鍵信息往往以文本的方式記錄在業務系統中,為了進一步分析重疾理賠經驗,需要對重疾賠案進行加工處理。過去常見的做法是由理賠或者精算人員對賠案進行手工清洗。在樣本量較小的情況下,這種方式具有快速、簡單、易操作的特點,但隨著理賠數據的快速不斷積累,手工清洗的局限性越來越明顯。

圖1 手工清洗與自動化清洗的對照
受益於計算機技術的不斷進步和發展,對於重疾理賠文本的清洗,瑞再提供了一系列持續優化的解決方案——基於人工智能的理賠文本自動化清洗工具。
入門
規則庫
規則庫以正則表達式為基礎。正則表達式,又稱規則表達式,是一個在傳統計算機語言學領域當中廣泛應用的算法。該方法旨在用特殊的字符規則描述、匹配給定文本當中需要匹配的字符串。
這種傳統的、基於專業知識構建的規則庫有著簡便、快速、易調整的特點,對於短文本的清洗有著較高的有效性和准確率,同時,對於複雜的長文本清洗,基於規則庫的方法也提供了一個初步但是快速有效的迭代起始點。
一個簡單用於匹配甲狀腺乳頭狀癌的
正則表達式示例
.*?((甲狀腺).*(乳頭狀癌?)).*
進階
統計模型
傳統的機器學習文本挖掘算法,首先通過分詞的方式,將一個文本變成一個由不同句子構成的句子集合,在這個基礎上采用概率模型,如隱馬爾可夫模型(HMM),將每一個句子變換成一個個的分詞短語。通過這種處理,文本被細化為由各種關鍵短語所構成的短語集合,在該集合基礎上,應用統計學的方式(比如單純計數的Bag of Word的方式,或者強調了詞語在文本和語料庫重要度的TF-IDF 方法)將文本轉換成計算機可以識別的向量表示,在此基礎上適用於我們對應的業務場景。
這種描述文本的方法,優點在於快速、直接,即整個單詞和文本由一種簡單且直接的方式變換成數學表示,但存在一定的局限性。
1)在我們做文本向向量轉換的時候,每一個分詞短語轉換成了一個向量表示,然而,這種方法並沒有真正意義上捕捉到每一個分詞短語的含義,每一個短語在文本當中周圍單詞的信息也沒有在計數的方式中得到體現,更不要提及中文當中的同義詞等對語義判斷的影響。
2)在算法實施層面,用這種方式給出的文本表達是一個非常大的矩陣,而這個矩陣當中有非常多的數字零,因此計算效率不高。
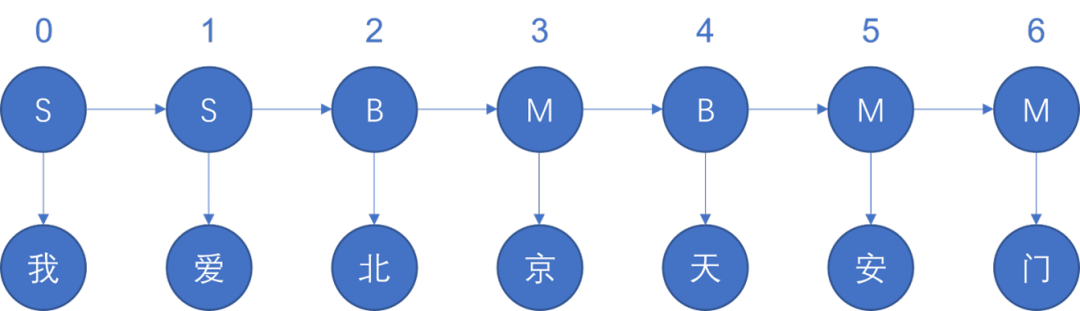
圖2 使用隱馬爾可夫模型的示例。該馬爾可夫模型由實際觀測到的信息(圖中的中文單詞)和隱藏信息(英文字母)構成。隱變量當中,S代表單一字,B代表詞組起始字,M作為詞組中間字。隱馬爾可夫就是使用概率論和動態規劃的算法,通過可觀測的中文,去判斷正確的隱變量的組成方式,從而達成分詞的目的。
高級
深度學習
深度學習引入了詞嵌入、注意力機制等方法,很大程度上解決了單純應用傳統統計模型存在的問題。
詞嵌入
我們可以通過word2vec的模型方案,建立起關鍵詞和周圍詞的關系,相比於詞袋模型,這樣的詞向量表示不再稀疏並帶有一定的語義信息,這種表達方式被稱為詞嵌入(word embedding)③ 。
注意力機制
在模型訓練時,另外一個重要的方法就是注意力機制。由於文本的序列化輸入,傳統的機器學習方法或者循環神經網絡模型無法“記憶”曆史信息。通過圖3右可以清晰的看出注意力機制能夠很好的考慮過往信息對當下信息的影響,從而有效的解決上述問題。

圖3 經典的循環神經網絡和注意力機制的神經網絡對比④
近年來,隨著在自然語言處理(NLP,Natural Language Processing)領域依靠詞嵌入和注意力機制的預訓練模型 + 模板學習的全新模型訓練範式的興起 ,我們可以直接使用已經被海量文本庫訓練好的大模型,從而極大了提高了模型效率。在此基礎上,通過設計訓練模板的方式 ,用少量但是經過專家標記過的數據,構建適用於目標文本的提示型模板,使得模型可以靈活的應用到下遊任務。
瑞再研發的基於人工智能的理賠文本自動化清洗工具,創造性融合了上述規則庫、現代自然語言處理方法以及深度學習模型。
在模型效率上,很大程度解決了在模型訓練中對海量人工標簽的依賴和專業人員的時間成本的問題;
在模型應用上,可以盡可能地適用於不同的理賠文本,輸出標准化的理賠文本分類信息;
在模型輸出上,融合的模型方案可以達到與專家清洗相一致的准確率。
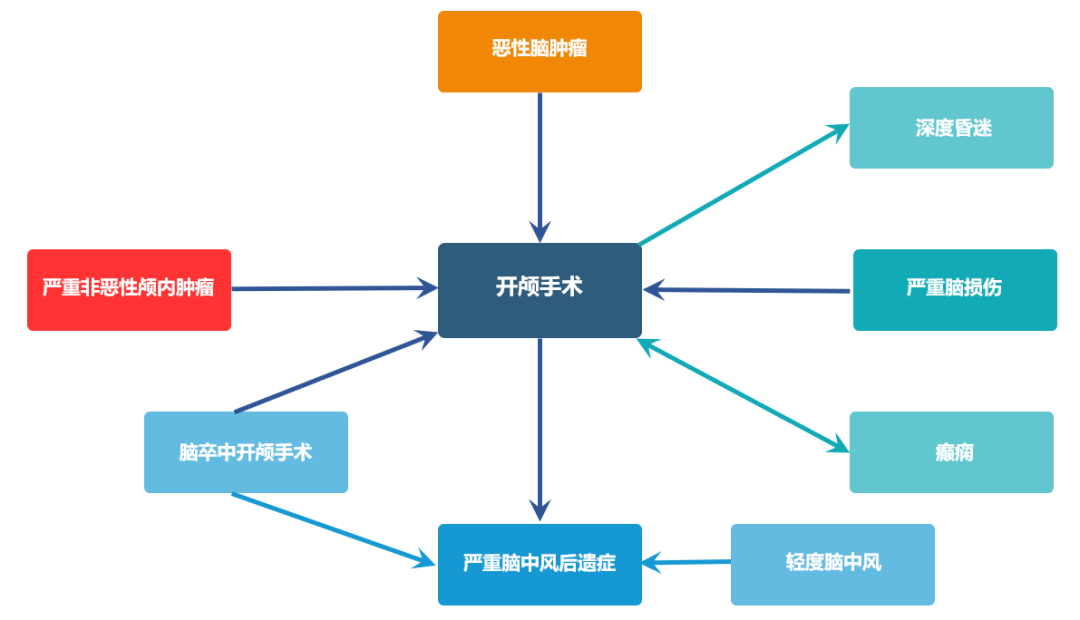
圖4 疾病相關性圖譜示例
通過瑞再智能理賠文本清洗工具搭建標准化、結構化的重疾理賠文本數據庫,將極大程度拓展保險數據開發和應用的深度和廣度。
傳統經驗分析的有效性和准確性得到進一步提升。如細化單病種經驗,更加深入的剖析發生率變化的驅動因素,繪制疾病相關性圖譜(圖4)等。
有力地支持重疾產品的開發創新。如輔助開發心腦血管特定疾病產品、三高人群特定疾病產品、糖尿病人群特定疾病產品等,填補保障缺口,提升保險保障力度。
風險預警。通過後端經驗追蹤、分類數據監測更好地預測重疾病種發生率的未來趨勢,助力重疾業務的可持續、健康發展。
▌本文作者
◆ 楊陽
瑞士再保險中國區壽險與健康險
高級定價創新精算師
◆ 黨曉芊
瑞士再保險中國區高級數據科學家
◆ 宋曉莉
瑞士再保險中國區壽險與健康險
理賠專家
參考文獻
① 中國精算師協會經驗分析辦公室. 中國人身保險業重大疾病經驗發生率表(2020)編制報告.
② 中國精算師協會經驗分析辦公室. 中國人身保險業重大疾病經驗發生率表(2020)編制報告.
③ Distributed Representations of Words and Phrases and their Compositionality,Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean. https://arxiv.org/abs/1310.4546
④ https://skymind.ai/wiki/attention-mechanism-memory-network


























































请先 登录后发表评论 ~